At the start of this blog I wanted to put useful information about image processing. I am going to continue. so
merry Christmas!
At the start of this blog I wanted to put useful information about image processing. I am going to continue. so
merry Christmas!
Posted in Image Processing | 2 Comments »
Posted in CBIR, Color Clustering, Content based image retrieval, Image Processing | 1 Comment »
Other image processing weblogs:
http://blogsearch.google.com/blogsearch?hl=en&q=image+processing&btnG=Search+Blogs
Posted in Image Processing | Leave a Comment »
This post is about image segmentation, as someone asked. My knowledge is poor in field of segmentation, but I have used a simple way of extracting feature, which is similar to a segmentation method. It uses image labeling to find the objects. In this method, color homogeneity of a region will be the criterion to define the objects.
First I explain the philosophy behind this method, then show you the implementation and its results.
You have to reduce the number of colors in you color pallet (result of quantizing color space) into some limited color batchs which we call them color labels, like: Blue, Dark Blue, Light Blue, Yellow, Light Yellow, etc. At this time you may have n Color labels. After that, you have to label each pixels of image with these labels. By doing this, these pixels will be divided into n classes. Then you can precess the relation of these pixels and find out the object of the images.
These are steps to do implement mentioned method:
Step 1: Create your own pallet .I reduced RGB color space into 216 colors of safe colors cube.

to:

Step 2: Cluster this pallet into some labels. I Clusters these 216 colors into 6 clusters/classes/labels, and then each clusters into 6 clusters/classes/labels, so I can label my pixels by 6 or 36. clusters/classes/labels are shown in the figure below. Each bin of 36 bins are one class of 36 classes, and each batch of 6 batches are one of 6 classes.

Step3: Assign a unique value to each class, and then label each pixel of your images by these values. I applied both [1, .. , 6] and [1, .. , 36] labels on some images which is shown below:

Step 4: Each object will be defined by a homogeneous color layout. Define its region and use it!
Some complicated and high-precision methods are available. You can find it by using your keywords in google and …
Posted in CBIR, Color pallet, Content based image retrieval, Image Processing, Image segmentation | 4 Comments »
As I promised, here is some useful notes about developing a complete image retrieval engine by using color and texture:
1. Image Gallery
Using a free database which have 1000 middle-sized image in 10 different categories
2. Feature Extraction
Some unique blocking methods are used to extract both features in the way that the main parts of image have higher impression and importance.
3. Clustering
I’ve used k-means algorithm to partition my feature space into 7 clusters, respect to 7 feature vectors previously mentioned. But the main criterion for decision is Histogram clusters.
I am not satisfied by using this method, so I am finding a better way to cluster my feature space. I found some articles which are concerned about this issue:
Thomas Deselaers, et al. “Clustering visually similar images to improve image search engines”, …
Ioan Cleju, et al. “Clustering by principal curve with Tree Structue”, …
Xin Zheng, et al. “Locality Preserving Clustering for Image Databse”, …
4. Similarity analogy
I’ve used level 1 of Minkowsky distance for histogram analogy and level 3 for texture-related features.
(For Minkowsky distance formula refer to: Long F. ; Zhang H. and Dagan Feng D., Fundamentals of content-based image retrieval, in Multimedia Information Retrieval and Management – echnological Fundamentals and Applications,” Springer-Verlag, pp. 1-26, 2003)
I’ve used reverse of calculated distance to find the similarity rank of each images. These ranks should be added together to calculate final rank of each images. At this point, IT SHOULD NOT BE FORGOTTEN TO NORMALIZE EACH RANK. Since each feature has different importance, different coefficient correspond to its importance should be multiplied into its calculated rank.
To know how to reach a normalized rank, I refer you to read this paper:
Li X. ; Chen S.C. ; M.L. Shyu and Furht B., “Image retrieval by Color, Texture, and Spatial Information,” in 8th International Conference on Distributed Multimedia Systems (DMS’2002), San Francisco Bay, California, USA, 2002, pp. 152-159.
5. Final Result
To find the similar images from database to a user-defined image, first of all, FV (=feature vector) should be extracted, using the same way as other images in database. Since I use 256-element histogram vector to partition image databse, the histogram part of FV have been used to find the respective cluster. After this step, the comparable images will be limited to the images belong to the respective cluster. Now, by using similatrity measure and finding the specific ranks and them add them in that special way, the similarity ranks will be assigned to every comparable images. The last thing to do is to sort this rates in descending order and show n-first high rank images to user.
Note that Each phase is capable to be improved.
Posted in CBIR, Content based image retrieval, Developing an image retrieval, Image Processing | 50 Comments »
Yesterday I heard something about Image Processing Libraries. There are some libraries which contains image processing main algorithms. You know academic algorithms are developed using matlab or some other open source mathematical applications, but they are just academic and not in purpose of business, because those algorithms works very slow. So, to develope a bussiness class application in field of image processing, some IDEs like visual-C will be used. These libraries designs for these purposes.
One of the most important of them is OpenCV which is developed by Intel and is compatible with Intel image processing chipset. Self intro of this library is:
Ch OpenCV package is Ch binding to OpenCV. ith Ch OpenCV package, C (or C++) programs using OpenCV C functions
can readily run in Ch without compilation.The latest Ch OpenCV package can be obtained from
http://www.softintegration.com/products/thirdparty/opencv/
or
http://openvc.sourceforge.net/Ch is an embeddable C/C++ interpreter for cross platform scripting,
2D/3D plotting, numerical computing and embedded scripting.
Ch is freely available from SoftIntegration, Inc.
http://www.softintegration.com
Some other libraries will be found in http://sf.net.
Posted in Image Processing, Image processing open library, OpenCV | 2 Comments »
As shown in the following figure, some major components of a CBIR are:
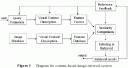
Row Images are stored into Image database. In order to fast access to these images, some descriptors should be extracted from them, which describe them in the best way. These descriptor appear into integer or real values, in order to be comparable. These values called Feature Vectors.
These vectors make it easy to classify images into some predefined classes by classification methods, or into non-predefined clusters by clustering methods. This is the duty of a block called indexing block.
Now, system is ready to accept the queries entered by user. This query appears as an input image, which is desired image for user. Actually user tells system that retrieve some images which is most similar to the quety image.
Search and retrieval Block uses send the query image to Feature Extraction block to extract its feature vector. Then uses it to search into classes/clusters to find out which kernel of these classes/clusters is nearest to the feature vector. Then some of most similar images to the query image retriev and show to user.
After these steps, user can see the retrieved images. Some systems give this opportunity to user to select the images which satisfy his/her more than others. Then this knowledge processes and affect the previus search result so that the result may be most satisfiable for user.
Some flowchart will be added soon.
View An Image retrieval system prototype in PERSIAN/Farsi /فارسی LANGUAGE. References section will be useful for all other languages, note that all of them are available for free. All of them are listed below.
Posted in CBIR, Content based image retrieval, Image Processing | 5 Comments »

Just look at this site:
I found video of a lecture about feature extraction. As you see, you are able to view current presenting slide beside its video!
Who said heaven is so far away…
Posted in Image Processing | Leave a Comment »
CBIR is about developing an image search engine, not only by using the text annotated to the image by an end user (as traditional image search engines), but also using the visual contents available into the images itselves.
Initially, CBIR system should has a database, containing several images to be searched. Then, it should derive the feature vectors of these images, and stores them into a data structure like on of the “Tree Data Structures” (these structures will improve searching efficiancy).
A CBIR system gets a query from user, whether an image or the specification of the desired image. Then, it searchs the whole database in order to find the most similar images to the input or desired image.
The main issues in improving CBIR systems are:
– – –
My final thesis is about improving a CBIR system by menas of learning algorithms. So I will write about it in detail here.
I am currently working on these issues:
Posted in CBIR, Content based image retrieval, Image Processing, Image search engine | 77 Comments »
If you are an AI student or graduated, you’ve may passed the course called “Fuzzy Logic”; atherwise, you’ve may heard about it.
“Fuzzy Logic” is about decision making, using uncertain observations. But there is certainty about the measurement of this ambiguity! (Is it confusing? Don’t worry; this is one of million amazing descriptions of this newborn logic!)
Fuzzy Logic was introduced by Prof. Lotfali Asker Zadeh (known as Prof. Lotfi Zadeh) at Berkley, and continued by Prof. Mamdani. These professors are both Iranian. So it is said that Fuzzy Logic was started and ended by Iranians.
I found this web page, when I wanted to find some articles about fuzzy image processing. It is the Homepage of Fuzzy Image Processing belongs to University of Waterloo, which takes the highest rank in Google. It is nice to know that here is managed by Prof. Hamid R. Tizhoosh, who is an Iranian professor too! 🙂
So despite that I am not an extreme nationalist, but I can conclude that Iranians have conquered the top of Fuzzy Logic!
– – –
Here is an abstract about Fuzzy Image Processing, to make us familiar with this issue:
Fuzzy image processing is the collection of all approaches that understand, represent and process the images, their segments and features as fuzzy sets. The representation and processing depend on the selected fuzzy technique and on the problem to be solved.
(From: Tizhoosh, Fuzzy Image Processing, Springer, 1997)
Posted in Fuzzi Image Processing, Image Processing, Iranian & Fuzzy Logic | 2 Comments »




{kind=link}
{kind=link}
{kind=link}